
Как найти полезные данные в недрах сайтов. Пошаговая инструкция «Если быть точным» по работе с «теневыми» API
Дисклеймер: В этом материале мы используем портал бухгалтерской отчетности ФНС в качестве учебного примера. При работе с недокументированными API рекомендуем обращать внимание на условия использования данных, которые публикуются на том или ином сайте. Если они прямо запрещают выгрузку данных, то лучше этого не делать. Также всегда следует помнить о правилах работы с отдельными типами данных, например, персональными данными. Даже если есть техническая возможность выгрузить их с помощью недокументированного API, это не всегда будет законно.
Что такое API и зачем они нужны
Если вы хотите получить водительские права или визу, то вам придется столкнуться с большим количеством бюрократических процедур: собрать документы, заполнить специальные формы, подать их, а затем ждать. Чтобы упростить обработку заявок, обычно для них создают шаблоны.
API (Application Programming Interface, программный интерфейс приложения) — это и есть набор таких шаблонов, своего рода цифровая бюрократия. Вы делаете запрос к удаленному серверу по заданному формату, ждете, пока ваш запрос обработается, и получаете результат в структурированном формате. Если упрощать, то API — это правила, по которым можно общаться с программой. Отправляете шаблонный запрос — получаете ответ в понятном и заранее определенном формате.
Подробнее почитать про API можно тут. В этом материале нас интересуют данные, которые возвращает API в ответ на запрос пользователя.
Некоторые API-интерфейсы создаются специально для того, чтобы с их помощью пользователи получали данные. Например, несколько сервисов API есть у платформы проверки и обогащения данных DaData. Другие известные примеры — API проекта Госзатраты, API сайта Госдумы, API со статистическим показателями Центрального банка или API государственного адресного регистра.
Порядок работы с такими сервисами подробно документируется. Разработчики API создают инструкции, в которых указано, какие запросы можно отправлять и в каком формате, в каком виде приходит ответ. Иногда (как в случае некоторых сервисов DaData) доступ к API платный, а число запросов ограничено.
У использования документированных и недокументированных API есть три основных преимущества относительно простого скрейпинга веб-страниц:
- Больше данных: иногда через API возвращается больше информации, чем отображается на сайте.
- Надежность: так как такие интерфейсы создаются в технических целях, они редко сильно меняются, а значит, можно регулярно собирать нужные данные. Правда, иногда официальные ведомства скрывают такие интерфейсы после журналистских расследований.
- Масштабируемость: скачать данные с помощью кода через API может быть проще, чем выгружать данные вручную. Для сбора данных, отображаемых на сайте, можно написать парсер (например, используя Python-пакеты Beautiful Soup и Selenium), но выгрузка данных с их помощью может быть намного медленнее, чем с помощью API.
Некоторые API — скрытые, но их все равно можно найти
Часто API, с помощью которых сайт получает данные, создаются в технических целях. То есть данные на сайт поступают через API, но как с ним работать, нигде не написано, потому что создатели сайта не предполагали, что к нему будут обращаться внешние пользователи. Такие API называют «недокументированными».
Технически работает все точно так же, как и в документированных API, но, заходя на сайт, вы не знаете, какие интерфейсы там есть. Однако их можно находить и использовать для автоматической выгрузки данных. Иногда часть информации, которую возвращает недокументированный API, доступна только в нем, а на сайте не отображается.
Например, на сайте Росприроднадзора в Реестре объектов, загрязняющих окружающую среду, в 2023 году в карточках объектов отображалась только общая масса выбросов, загрязняющих веществ. А в API, который передавал эти данные сайту, масса выбросов была разбита по конкретным загрязняющим веществам. Воспользовавшись таким недокументированным API, мы оценили, где расположены самые опасные загрязняющие объекты и какие самые опасные вещества они выбрасывают. Правда, через несколько месяцев после публикации Росприроднадзор удалил API, а совсем недавно закрыл и весь реестр.
Другой пример — портал бухгалтерской отчетности ФНС, на котором данные бухгалтерских и финансовых отчетов компаний тоже передаются через недокументированный API. Если научиться с ним работать, то получится, например, выгрузить данные о финансовых результатах организаций, которые вас интересуют.
API нередко используют в журналистских расследованиях. В 2019 году журналисты и исследователи обнаружили, что «умные» дверные звонки со встроенными камерами используются правоохранителями — и сеть таких устройств слежки постоянно растет. Для этого они с помощью недокументированного API выгрузили данные приложения Ring Neighbors, в котором владельцы «умных» звонков делились с соседями видео- и текстовыми сообщениями об обстановке в их районе. Другого способа получить такие данные не было.
Другой пример — исследование BBC о доступности гормональной терапии для женщин. Авторы, используя недокументированное API, собрали данные о расположении клиник Национальной службы здравоохранения, в которых работают специалисты по женскому здоровью, и выяснили, что в 59% районах их нет. Поскольку в других источниках таких данных не было, альтернативой API был бы ручной сбор данных. Это заняло бы гораздо больше времени, чем автоматическая выгрузка через API.
Инструкция: ищем недокументированный API
Разберемся, как с минимальными навыками программирования, используя только функции для разработчиков (DevTools) в браузере Google Chrome или Firefox, найти недокументированное API. В качестве примере используем сайт бухгалтерской (финансовой) отчетности ФНС.
Шаг 0. Открываем нужный сайт
Заранее сказать, на каких страницах сайта используется API, сложно. Вероятно, вам понадобится повторять шаги, описанные ниже, несколько раз. Но чаще всего API используется там, где информация выдается в структурированном виде по многим объектам (например, на странице есть списки из множества других страниц или таблицы).
В случае портала ФНС такая страница открывается, если воспользоваться функцией расширенного поиска портала бухгалтерской отчетности.
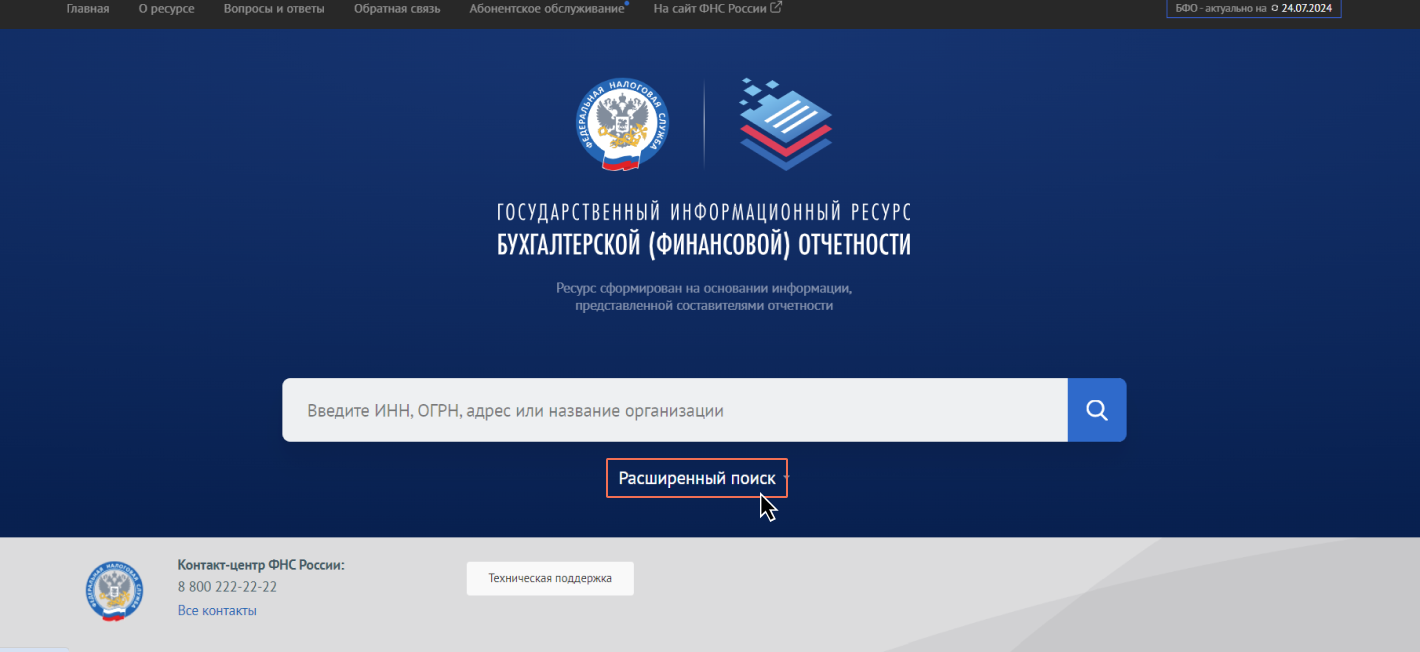
Шаг 1. Открываем панель инструментов веб-разработчика
Чтобы в Google Chrome открыть Панель инструментов разработчика, достаточно кликнуть правой кнопкой мышки в любом месте веб-страницы и выбрать пункт «Просмотреть код». Не перепутайте: пункт «Просмотр кода страницы» предназначен для других целей.
Есть и другие способы открыть панель инструментов:
- Кнопкой F12;
- Сочетанием клавиш — Ctrl + Shift + I в Windows или Command + Option + I в macOS.
- Через меню: нажимаем на три точки → «Дополнительные инструменты» → «Инструменты разработчика».
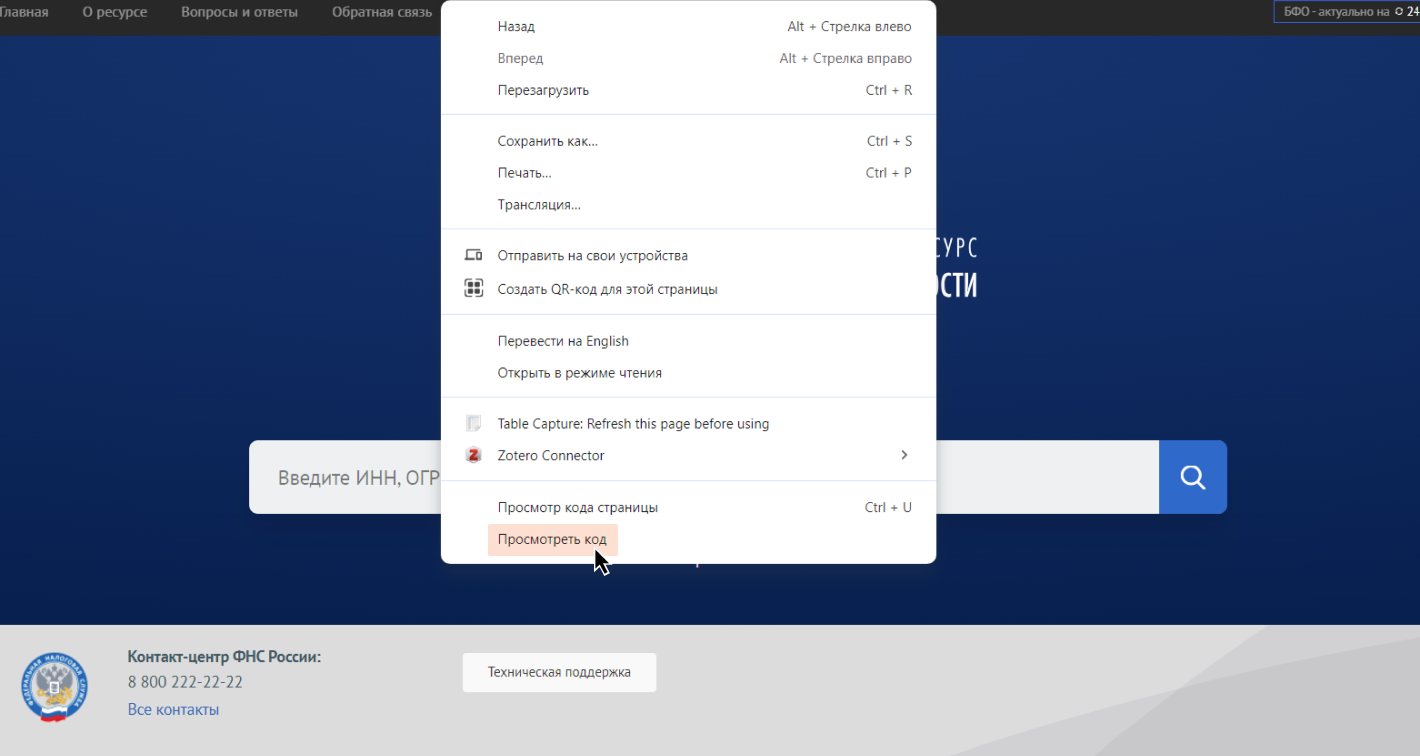
Откроется окно с большим количеством различных элементов. Например, на панели «Elements» можно увидеть исходный код, из которого собирается та веб-страница, которую вы открываете. Там есть и другие полезные функции, но нас будет интересовать вкладка «Network» — именно она позволяет смотреть, через какие интерфейсы браузер получает информацию, и в частности находить API .
Шаг 2. Переходим во вкладку Network панели инструментов
На вкладке Network отображаются запросы и их результаты ко внутренним и внешним ресурсам. Именно здесь можно найти запросы, которые передаются через недокументированные API.
Все, что вы видите на сайте, приходит из какого-то источника. Текст, картинки, данные, код сайта хранятся на удаленном сервере, и должны попасть к вам на устройство и отобразиться в браузере. Тут же можно обнаружить запросы, которые отправляют и получают различные рекламные инструменты, чтобы собирать пользовательскую статистику.
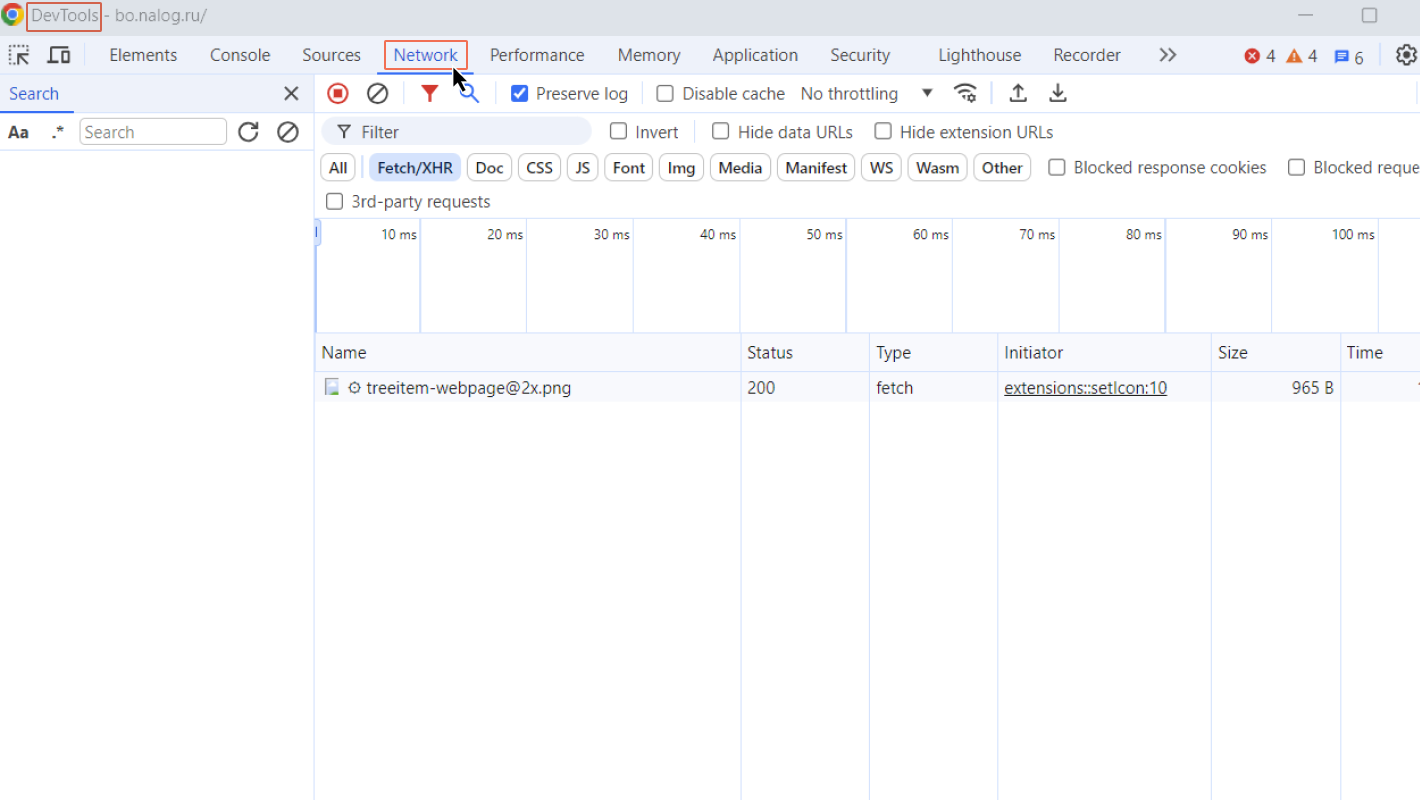
Шаг 3. Открываем страницу с результатами запроса
Теперь сверните «Панель инструментов разработчика» и через опцию расширенного поиска на сайте ФНС выберите все отчеты за 2023 год («Расширенный поиск» → «Отчетный период» → 2023 год). После этого вернитесь в окно «Панели инструментов разработчика».
На других сайтах на этом этапе вам будет нужно или обновить страницу, на которой вы ищете недокументированный API, или найти на сайте ту страницу, на которую, как вы предполагаете, передаются данные через недокументированный API. Как мы уже отмечали, часто API используется там, где информация отображается на сайте в структурированном виде — таблицах, дашбордах, интерактивных графиках.
Если вы сначала открыли страницу сайта, и только потом панель инструментов, то на вкладке Network ничего не будет (как на скрине выше) — все необходимые данные уже были переданы. Нужно обновить страницу, или, например, нажать на конкретную компанию, чтобы во вкладке Network отобразились запросы, через которые ваше устройство будет получать данные с удаленного сервера.
Во вкладке Network на панели инструментов вы увидите большое количество различных типов запросов. Например, там есть гифки (Type: gif), есть код (Type: script). Это все элементы, из которых собирается веб-страница.
Нас будет интересовать тип Fetch/XHR (API, доступный в скриптовых языках браузеров, таких как JavaScript), который как раз используется для передачи данных. Чтобы было проще искать нужные запросы, на вкладке Network есть фильтры, которые позволяют отбирать нужные типы запросов (All — все, Fetch/XHR — данные через API скриптовых языков, Img — картинки и другие). Если вдруг вы не видите запросов во вкладке Network, то стоит проверить, что настроен фильтр на нужный тип, или выбрать опцию All.
Видим, что с типом fetch есть запрос organizations/?allFieldsMatch=False&period=2023&page=0. Даже из названия понятно, что этот запрос возвращает данные по организациям за 2023 год.
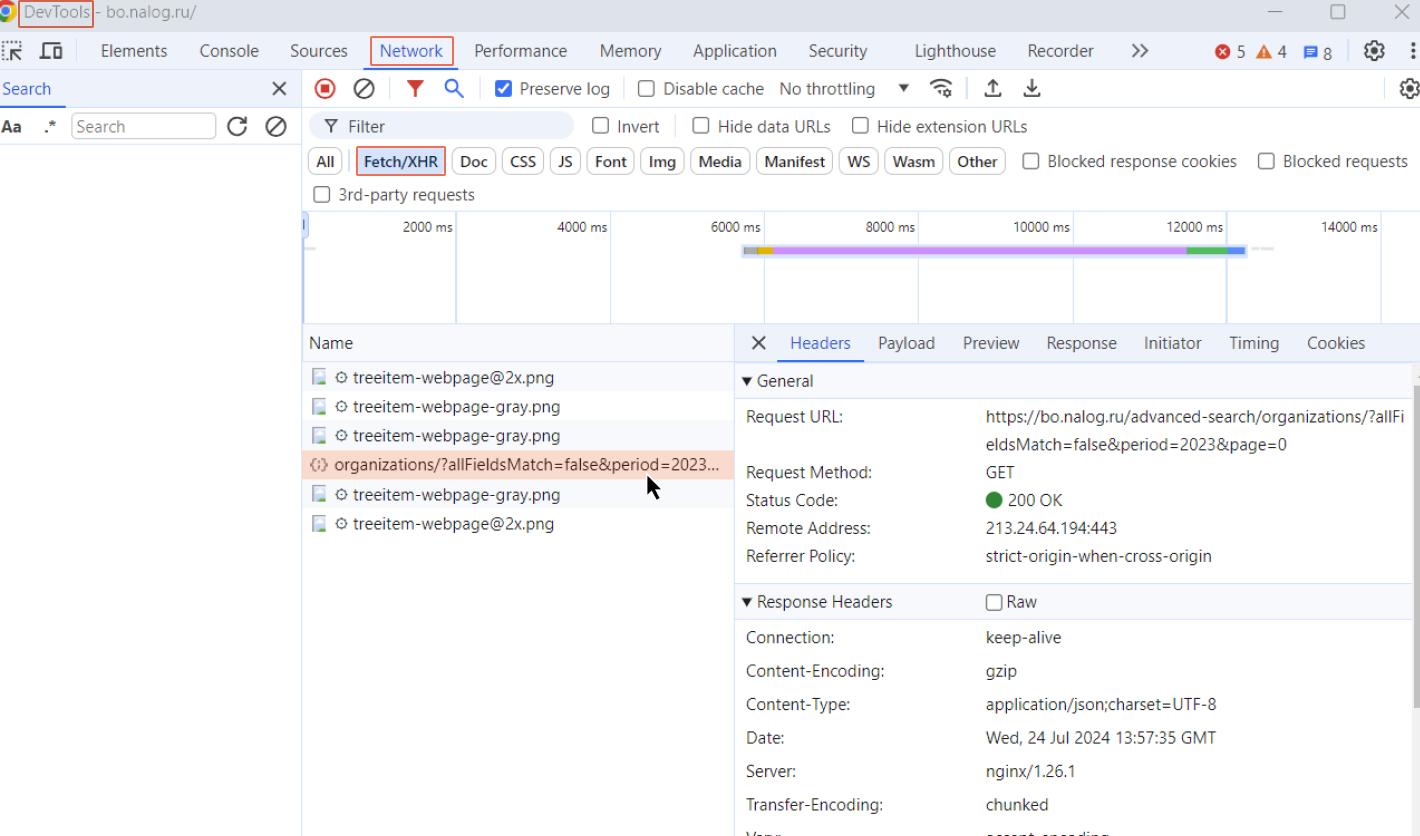
Шаг 4. Изучаем выдачу
Давайте кликнем на него. Может возникнуть вопрос, как сразу понять, какой запрос отвечает за доставку данных на сайт. Честный ответ — сразу никак. Придется вручную посмотреть разные запросы: какие у них названия, какие параметры запроса, что возвращается. Но есть несколько признаков, которые помогут определить, что запрос возвращает именно данные:
- большой объем информации — чем больше данных, тем больше будет весить ответ на запрос;
- осмысленные названия — обычно даже в недокументированных API разработчики стараются называть методы так, чтобы было примерно понятно, за что они отвечают;
- в запросе есть знак ?, который сигнализирует о наличии параметров, которые можно в него передавать.
После клика на конкретный запрос откроется новое окно. В нем есть вкладка Headers. В ней описана структура запроса, которую ваш браузер отправил на сервер. Как мы и говорили, запрос не произвольный, а имеет ряд обязательных элементов.
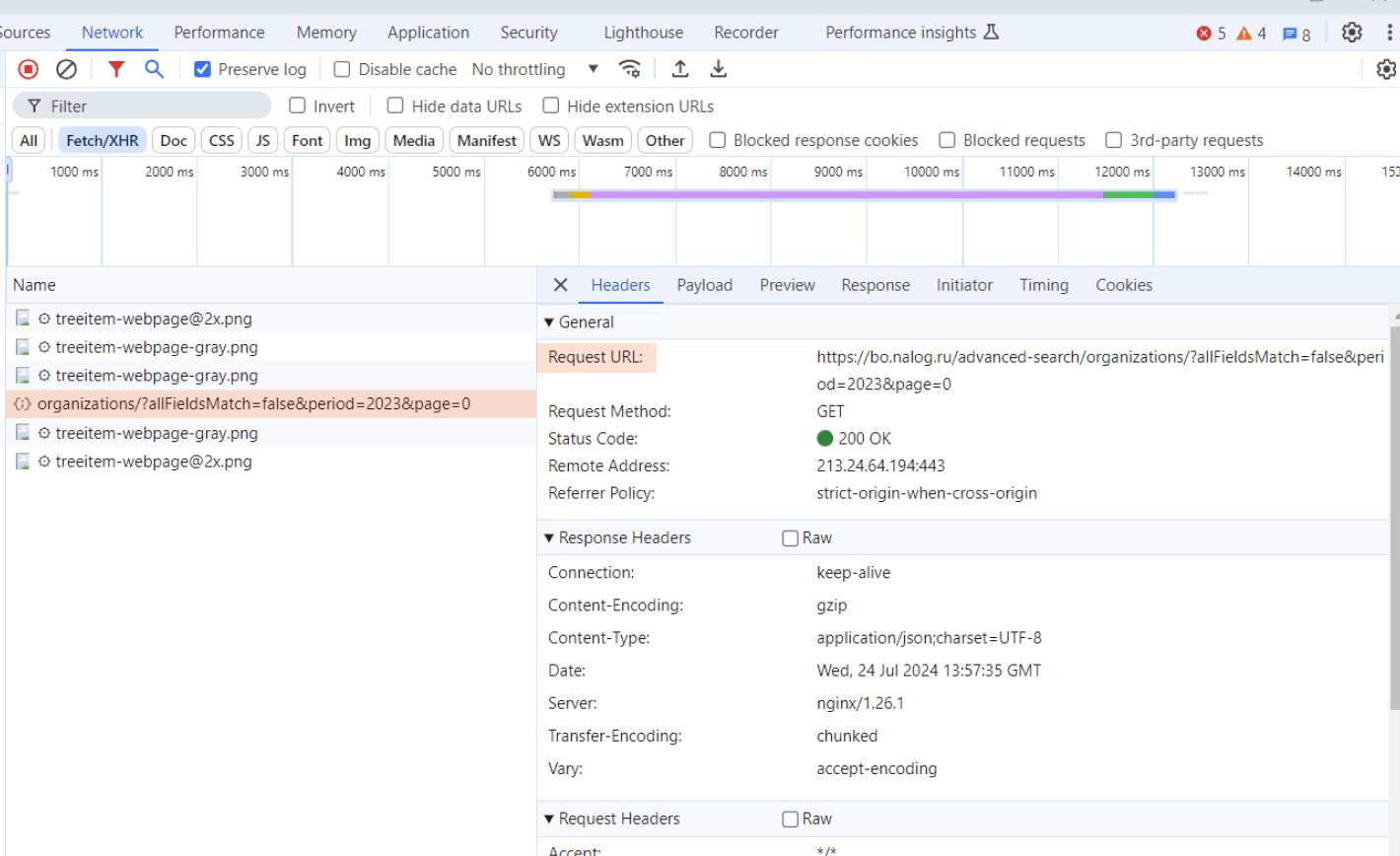
В частности, есть URL-ссылка в поле Request URL: https://bo.nalog.ru/advanced-search/organizations/?allFieldsMatch=false&period=2023&page=0
Ссылка API-запроса обычно состоит из несколько частей:
- протокола (https);
- домена (bo.nalog.ru);
- путь (advanced-search/organizations/);
- параметры запроса (allFieldsMatch=false&period=2023&page=0).
Для запроса данных отчетности по организациям используется путь advanced-search/organizations/ с тремя параметрами: allFieldsMatch=false (отметка о том, что опция поиска по всем полям из расширенного поиска не используется), period=2023 (мы запрашивали данные за 2023 год) и page=0 (данные о компаниях выводятся не одним огромным списком, а небольшими частями). Параметры можно менять, и получать все новые и новые данные.
Ответ, полученный на запрос, отображается во вкладке Response. Именно здесь мы видим те данные, которые вернул API. Выглядит все достаточно сложно, но формат ответа опять стандартизован. Как правило, ответы возвращаются в JSON-формате. Это пары ключ-значение, где ключи заранее известны, а значение для каждой компании свое.
В нашем случае, например, по ключу id указано значение 29827 — это уникальный идентификатор первой компании из выдачи, для которой есть данные об отчетности в 2023 году. Есть и номер ИНН этой компании в поле inn, и аккуратно разбитый на отдельные элементы адрес юридического лица.
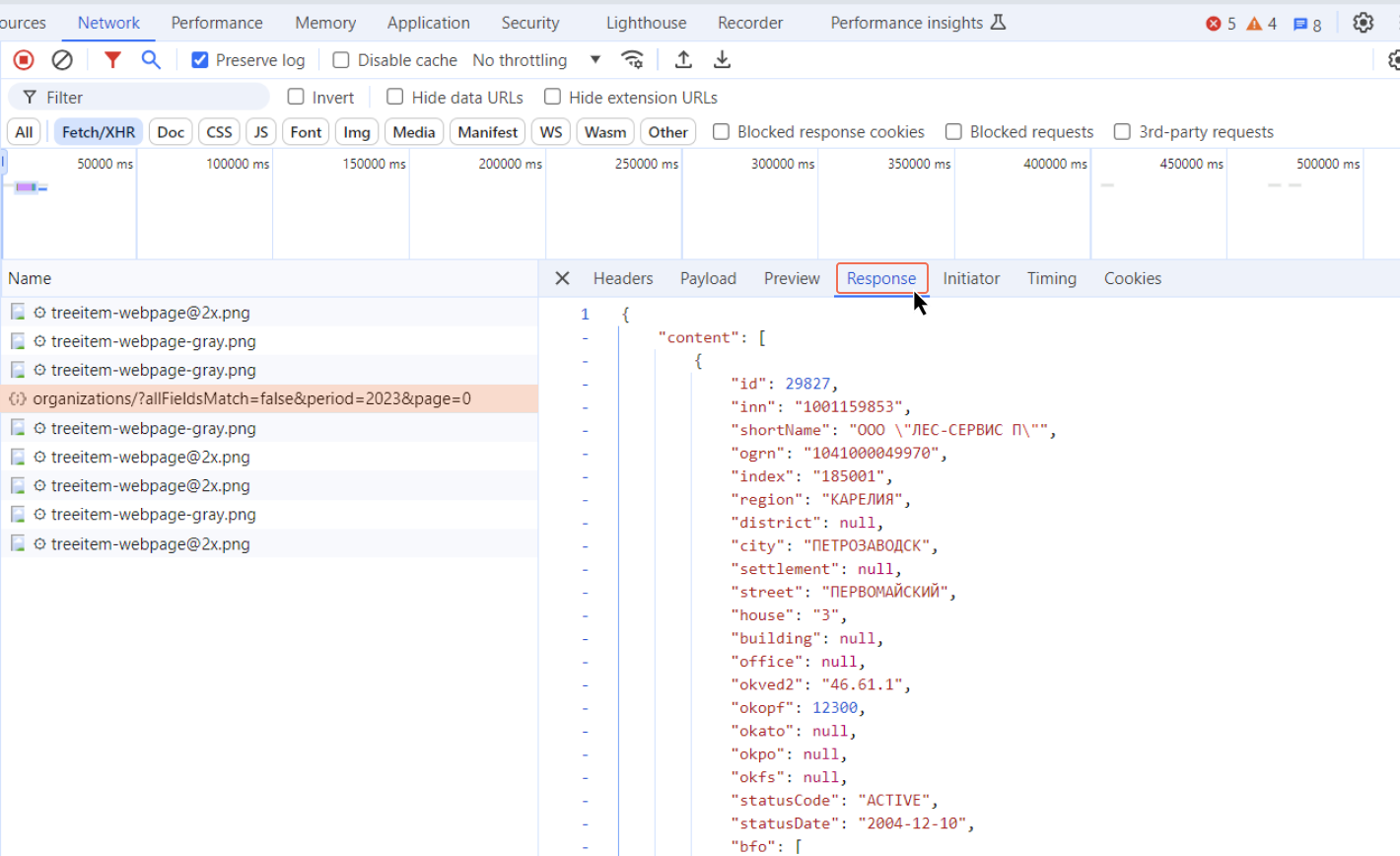
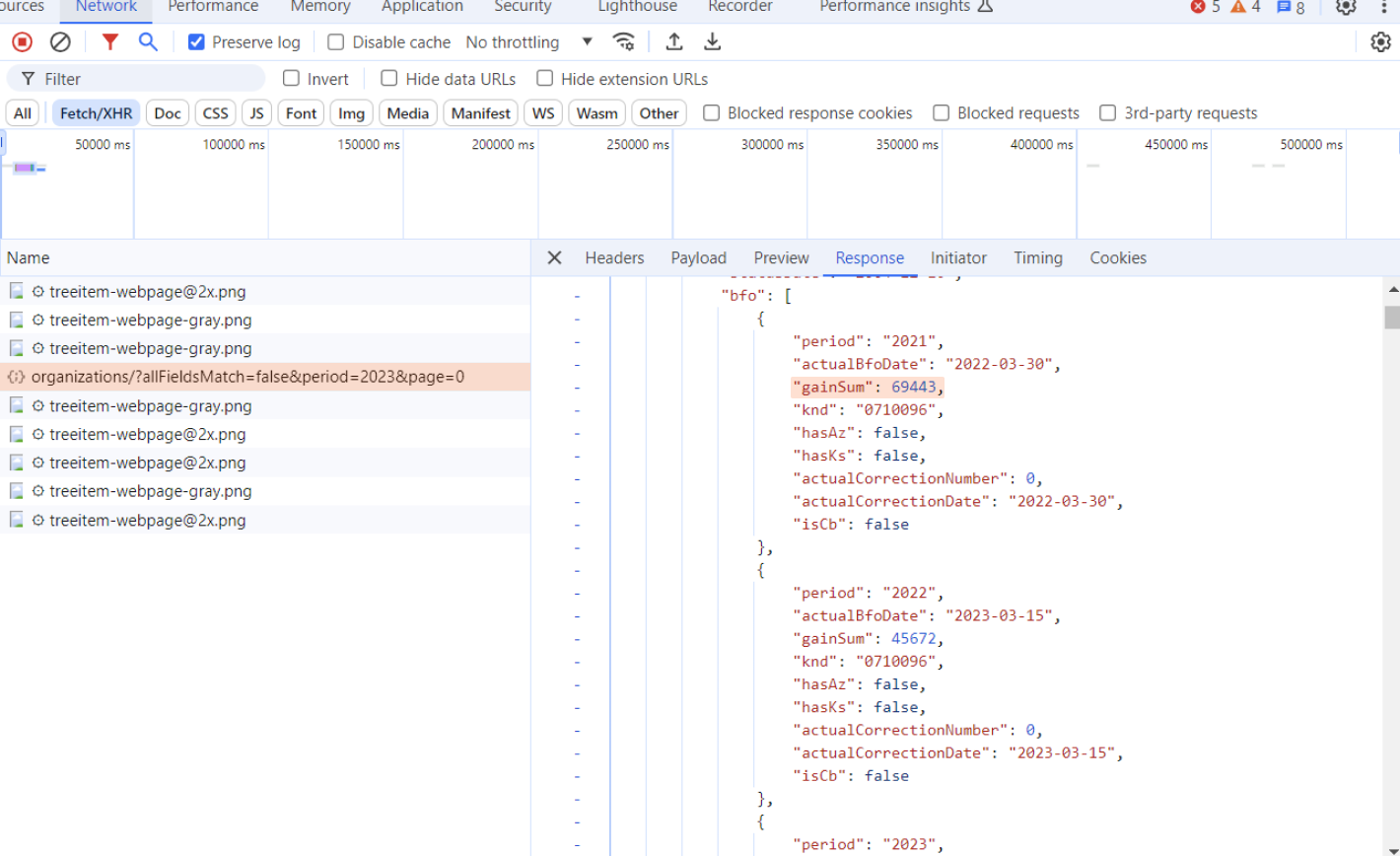
Данных вернулось довольно много. Если полистать дальше, то мы увидим те данные, которые на сайте еще даже не отобразились. Например, суммы полученной выручки по годам.
Шаг 5. Копируем ссылку на запрос
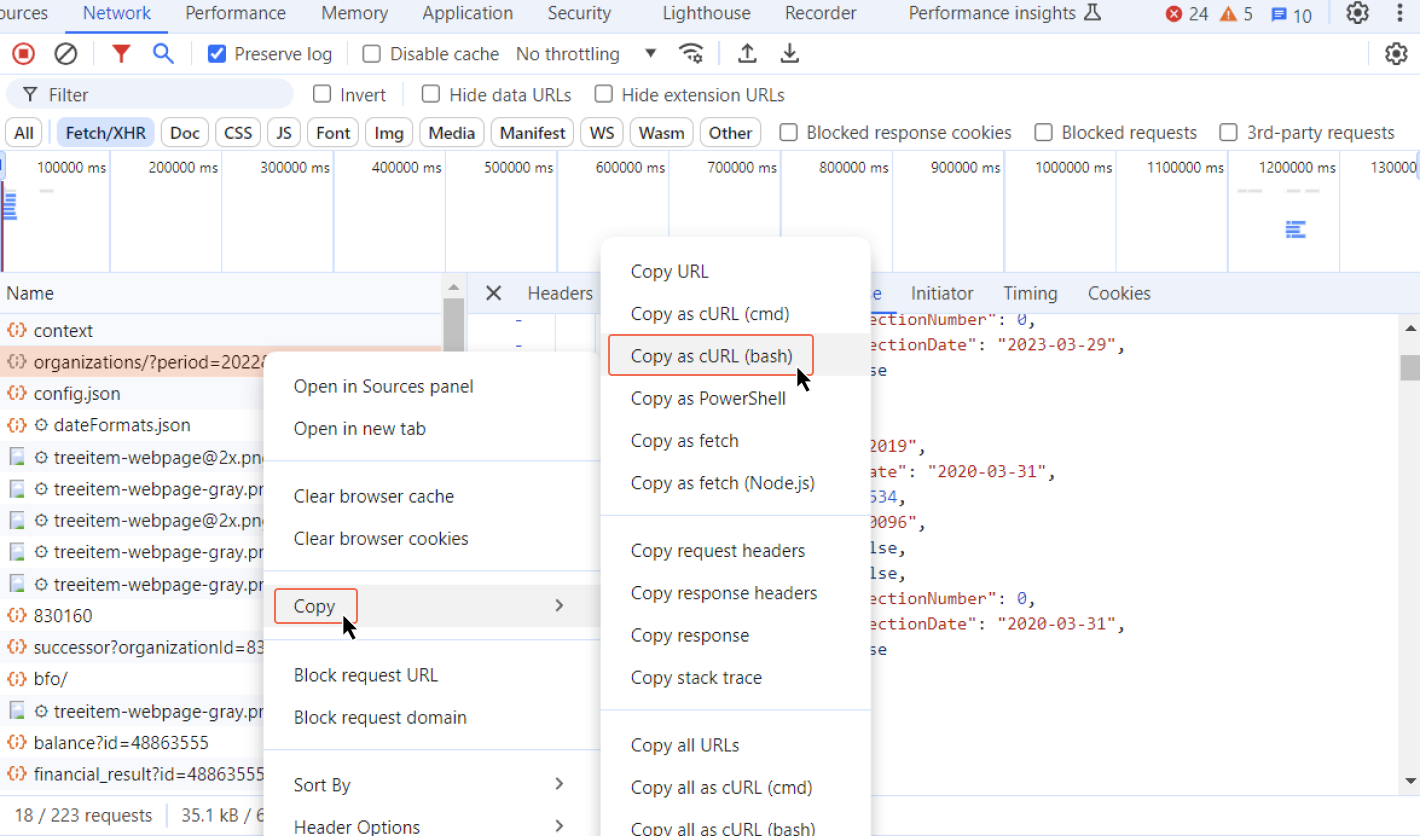
До этого момента мы вручную в панели инструментов смотрели на данные, которые возвращает недокументированный API. Но что если процесс выгрузки и сбора данных, хочется автоматизировать, например, с помощью кода на Python? На Шаге 4 мы уже нашли URL-ссылку на запрос и различные параметры запроса. Можно скопировать их вручную и вставить в код, чтобы автоматически собирать данные. Но можно сделать все еще быстрее.
Для этого на вкладке Network достаточно кликнуть правой кнопкой мыши на нужный запрос. И затем выбрать «Copy-Copy as cURL(bash)». Теперь полная ссылка со всеми нужными параметрами скопирована, осталось подогнать ее под формат конкретного языка программирования.
Можно использовать и пункт «Copy URL» — он вернет только саму ссылку запроса без других важных параметров, например, с информацией о браузере и информационной системе, которые могут понадобиться, когда вы будете встраивать найденный API в код.
Шаг 6. Конвертируем ссылку в код на Python
Чтобы преобразовать скопированный cURL в API-запрос на конкретном языке программирования и автоматизировать процесс выгрузки данных, можно использовать сайт curlconverter.com. Вставляем скопированную ссылку в окошко curl command, и получаем готовый код.
На скрине ниже мы создаем код на языке Python в стандартной библиотеке requests. Можно выбрать любой другой язык или фреймворк.
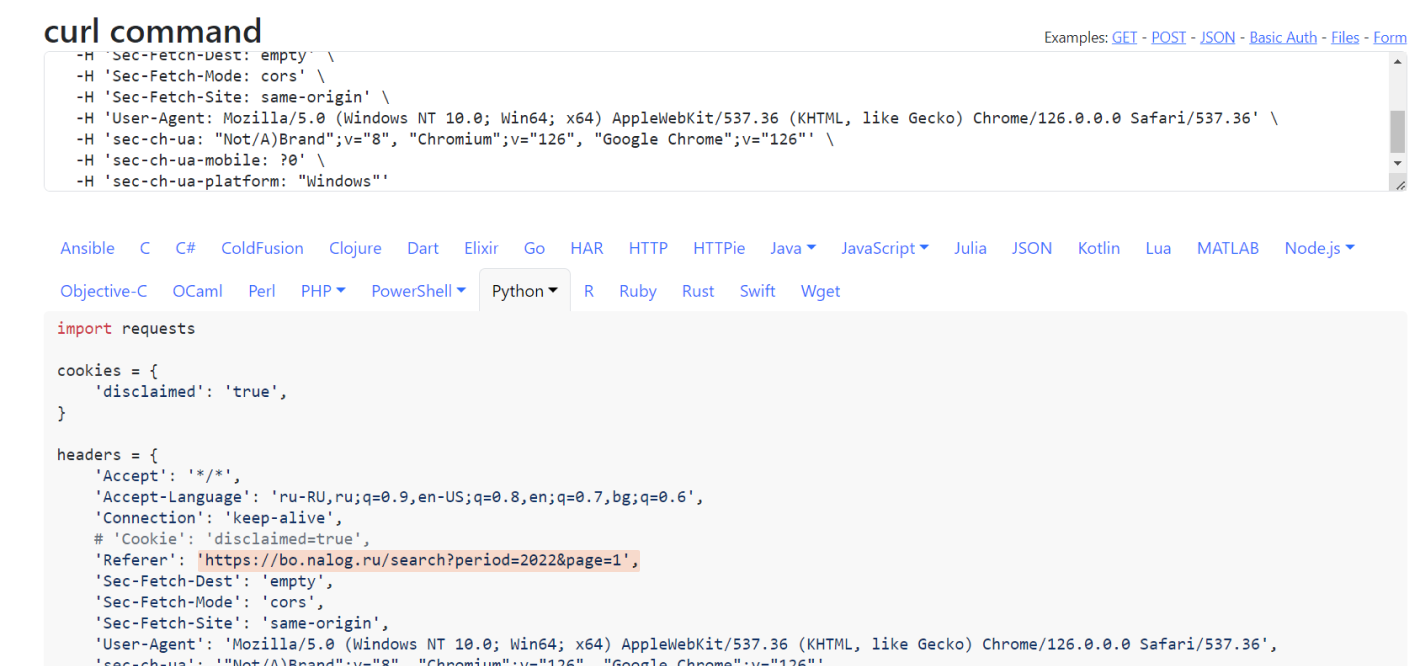
Теперь у нас есть готовый код, который можно дорабатывать и встраивать в собственные модули.
Быстро протестировать его работоспособность можно, например, в Google Colab. Чтобы после запуска кода посмотреть на результат запроса, достаточно ввести:
response.json()
Пример с кодом можно найти по ссылке.
Как автоматизировать сбор большого объема данных
Метод advanced-search/organizations, который мы разобрали выше, возвращает список организаций с финансовой отчетностью за конкретный год. У него, как мы выяснили, есть параметр page. Сначала значение этого параметра равно 0 — API вернет список из первых 20 организаций. В коде можно менять значение этого запроса на 1, 2 и так далее, чтобы получать данные о следующих организациях.
Если вы кликнете на конкретную организацию из списка, то выяснится, что ФНС также использует метод nbo/organizations/x, где x — уникальный идентификатор организации. Таким образом, вы сначала с помощью кода можете пройтись по всему списку организаций, собрать общие данные о них, а затем, используя уникальные идентификаторы, собрать более подробную бухгалтерскую отчетность по каждой компании.
Если при чтении этого гайда у вас появились вопросы или что-то не получилось, пишите в бот «Если быть точным» и вступайте в наш чат про открытые данные.
Автор: Александр Кейсут